

Some literature related in this problem have been studied. First literature is rapid estimation of fat content in salmon fillets by color image analysis. This research done by Stien et all in 2007 has aim to develop a method for automatic a fat content in salmon fillets by means of image analysis and use this to determine the area of white stripe visible on the fillets surface compared to total area of the fillet. The method that used is on steps following:

Step-2: Discrimination of the lipid stripes from other parts of the fillet. Using a global threshold where in a large area of false segmentation for all possible threshold values in both the G and B color layers. In the image, the muscle in the abdomen typically has the same color as the fat strips in other parts of the fillet. This is probably caused both by non-uniform lighting on the scene and difference in pigmentation between different parts of the fillet. Applying the 3x3 median filters on G-layer to remove noise. Then apply adaptive threshold.
Step-3: Estimation of fat content by image analysis.
Second literature is development of a hybrid image processing algorithm for automatic evaluation of intramuscular fat content in beef M. longissimus dorsi. This research aims to separate the lean from the other part fat and background by extract intramuscular fat (IMF) particles within the LD muscle from structural features of inter-muscular fat surroundings the muscle. This method as follows:
Step-1: Noise removal. To remove the noise we have to compare the pixel with the other neighbor pixels and make a region and give the weight. Concern on the color and distance of two pixel that called (ζ,x). x is the pixel that will be determined as noise or not and ζ is the neighbors that will be compared.
Step-2: Segmentation. This research use unsupervised clustering methods, the fuzzy c-means for segmentation. The advantage is that each image pixel has a membership grade indicating its belongingness degree to each cluster by the introduction of fuzziness. But, the problem is FCM does not incorporate information about spatial context, causing its sensitivity to noise and other imaging artifact. Another problem is FCM use Euclidean space to measure the similarity between prototype and data points, with fail on separation boundary cluster in nonlinear case.
Materials and Method
Sample Preparation
Experimental samples were provided by Institute the Research and Technology Food and Agriculture (IRTA), Gerona, Spain. The method that used to gain the images is using FoodScan. This equipment is based on near infrared transmission (NIT) and is a non-destructive technology used to determine different parameters in food products. From a tungsten-halogen lamp, light is guided through an optical fiber into the internal moving-grating monochromator, which provides monochromatic light in the spectral region between 850 and 1050 nm. The light is transmitted through the sample, and the unabsorbed light strikes a detector. The detector measures the amount of light and sends the result to the digital signal processor, which communicates with the personal computer (where the final results are calculated thanks to a previously developed calibration to determine fat content).
The sample is placed in a cup and positioned inside the FoodScan sample chamber. The sample cup is rotated during the analysis process to sub scan various zones of the test sample, which are then merged together for the final result. This procedure provides a more representative result from potentially nonhomogeneous samples.
Besides take the images, IRTA also retrieve the ground truth data of fat content using SOCTEX. This equipment is based on a chemical method which has two steps. In the first step, an acid digestion is carried out. In this step the fat that is bound to other non-solvent soluble as e.g. proteins are separated. This step allows the bound fat to be extracted in the solvent extractions.
In the second part is carried out an extraction with hexane. This step in turn is divided into three times: boiling time, rinsing time and recovery time. The objective is completely dragging the fat contained in the sample. Then weighed the fat extracted.
Preprocessing Step
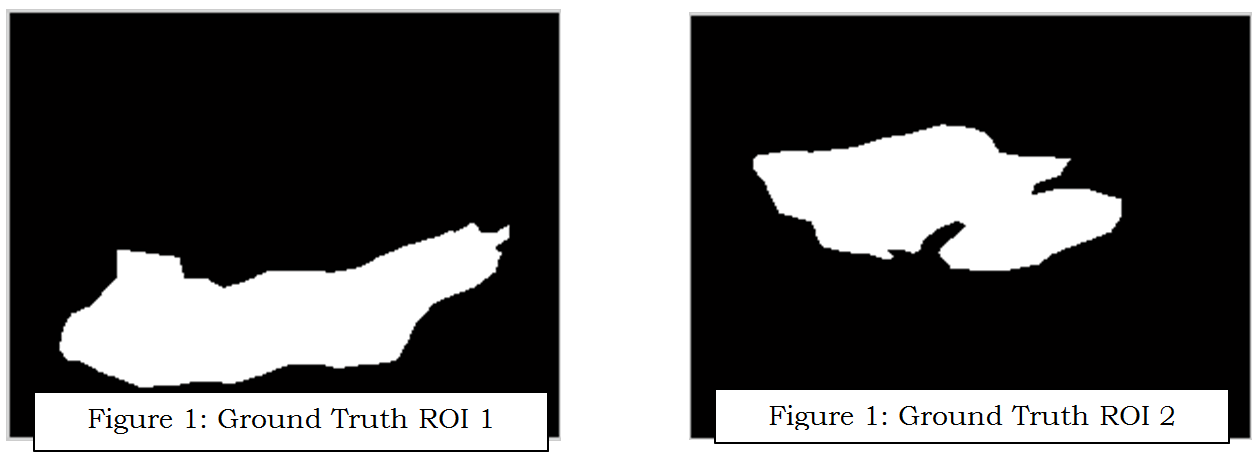
This step has objectivity to gain two regions of ham area by segmentation process. The original image has wide resolution, the first step is cropping image and apply threshold and median filter 10 by 10 size of windows to remove the background and masking. To get the ham area Gaussian filter using 3 by 3 size of windows, normalization, and threshold on 0.1 and 0.6 to make mask of ham area. From this result there are conditions that the ham area has been divided become two regions or not yet. If already divided the process is done, but if not yet have to find the Inter-muscular fat that will split the area. By invert, normalization, and adaptive threshold we can retrieve the IMF (Inter-muscular Fat), and also region threshold applied to remove the noise. The adaptive threshold is worked to find the outer shape too.
This process has condition that IMF can be detected or not, it is depends on threshold, but to make it automatic, the condition should be work by find the center from the outer shape. However if we found the Inter-muscular we can use the center area of this area. This center will be used to reconstruct the Inter-muscular to be able split the region. Using minimum distance (Ecludiance distance applied) the line between center and nearest point of outer shape developed using linear interpolation and morphological operation. The final stage labeling and boundary applied to get the two regions. The whole process can be seen in Figure 3.
Fat Content Extraction
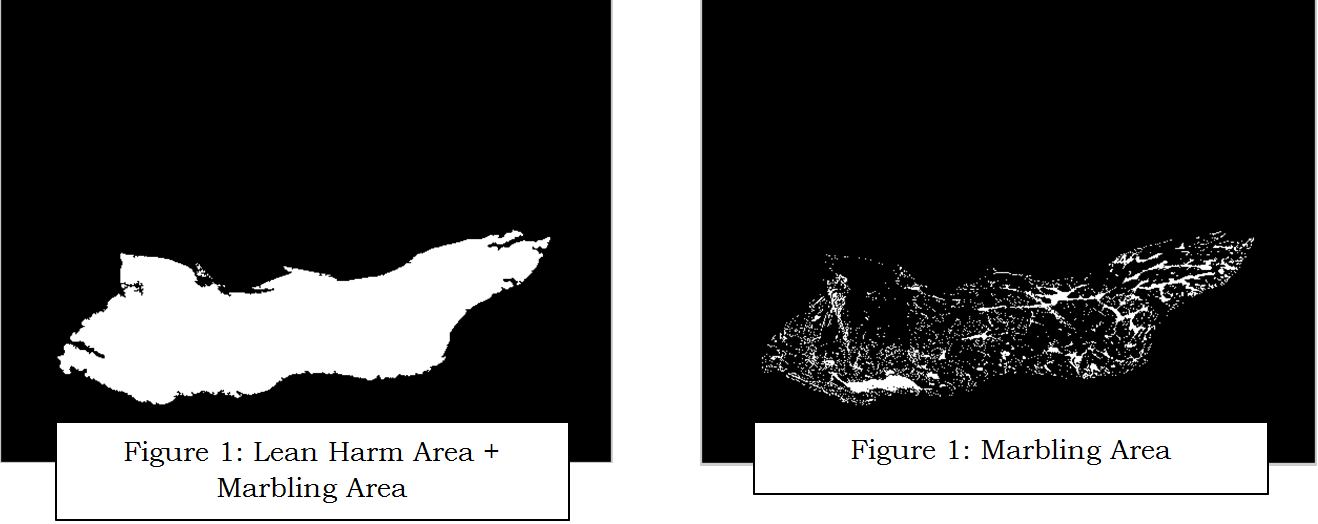
Two steps were developed to perform the contrast enhancement. The first step used twice the green channel to create the grey image (DoubleGreen) and the second used the product of the red, green and blue channels to create the grey image (TotalMix). For DoubleGreen, observation of the red, green and blue channels showed that contrast between lean muscle and marbling fat was noticeable in the green channel. When the DoubleGreen image was then subtracted marbling pixels dropped to or very near zero and muscle pixels returned to their values in the DoubleGreen image. Tripling of this image created a robust contrast between muscle and marbling pixels. For TotalMix, observation of pixel values in a full RGB color image showed that muscle pixels had lower values in all three color channels. The contrast enhancement and fat content extraction can be observed on Figure 3.


Result of the algorithm above is divided to three parts. First part is the preprocessing result and the second is fat content extraction. The final result is visualization fat content (marbling fat) on chart.
1. Preprocessing Result
Preprocessing result is related on segmentation step results that have been described before. The final result of segmentation can be seen clearly in the last image of this part.

 The Inter-muscular reconstrution result is here.
The Inter-muscular reconstrution result is here.





This result contains two kind plotting data result. The first one is the accuracy of segmentation process that divide ham area become two regions. The measurement that used is Jaccard Coefficient and Dice Coefficient. Almost all of the image have been segmented successfully upper 90% based on Dice Coeeficient and all image 70% success segmented based on Jaccard measurement.



REFFERENCESS
- Patrick Jackman, Da-Wen Sun, and Paul Allen, Recent advances in the use of computer vision technology in the quality assessment of fresh meats, Trend in Food Science & Technology, 22 (4) (2011), pp. 185–197.
- J. Jia, A.P. Schinckel, J.C. Forrest, W. Chen, and J.R. Wagner, Prediction of lean and fat composition in swine carcasses from ham area measurements with image analysis, Meat Science, 85 (2) (2010), pp. 240–244.
- L.H. Stien, A. Kiessling, F. Manne, Rapid estimation of fat content in salmon fillets by colour image analysis, Journal of Food Composition and Analysis, 20 (2) (2007), pp. 73–79.
- N. A. Valous, K. Drakakis, and Da-Wen Sun, Detecting Fractal Power-law Long-range Dependence in Pre-sliced Cooked Pork Ham Surface Intensity Patterns Using Detrended Fluctuation Analysis, Meat Science, 86 (2) (2010) 289-297.
- F. Mendoza, N. A. Valous, Da-Wen Sun and Paul Allen, Characterization of Fat-Connective Tissue Size Distribution in Pre-sliced Pork Hams Using Multifractal Analysis, Meat Science, 83 (4) (2009) 713-722.
- C. J. Du, Da-Wen Sun, P. Jackman and P. Allen, Development of a Hybrid Image Processing Algorithm for Automatic Evaluation of Intramuscular Fat Content in Beef M. Longissimus dorsi, Meat Science, 80 (4) (2008) 1231-1237.
- Tan J, Meat quality by computer vision, Journal of food engineering, 61 (1) (2004), pp. 27-35.











